flowchart TB
A[model] --> B(assumptions)
B --> C[fit] --> D{check} -->|adequate| E(stop)
D --> |not good| B
Regression
Example
Figure 1 Abdominal circumference against gestation age.
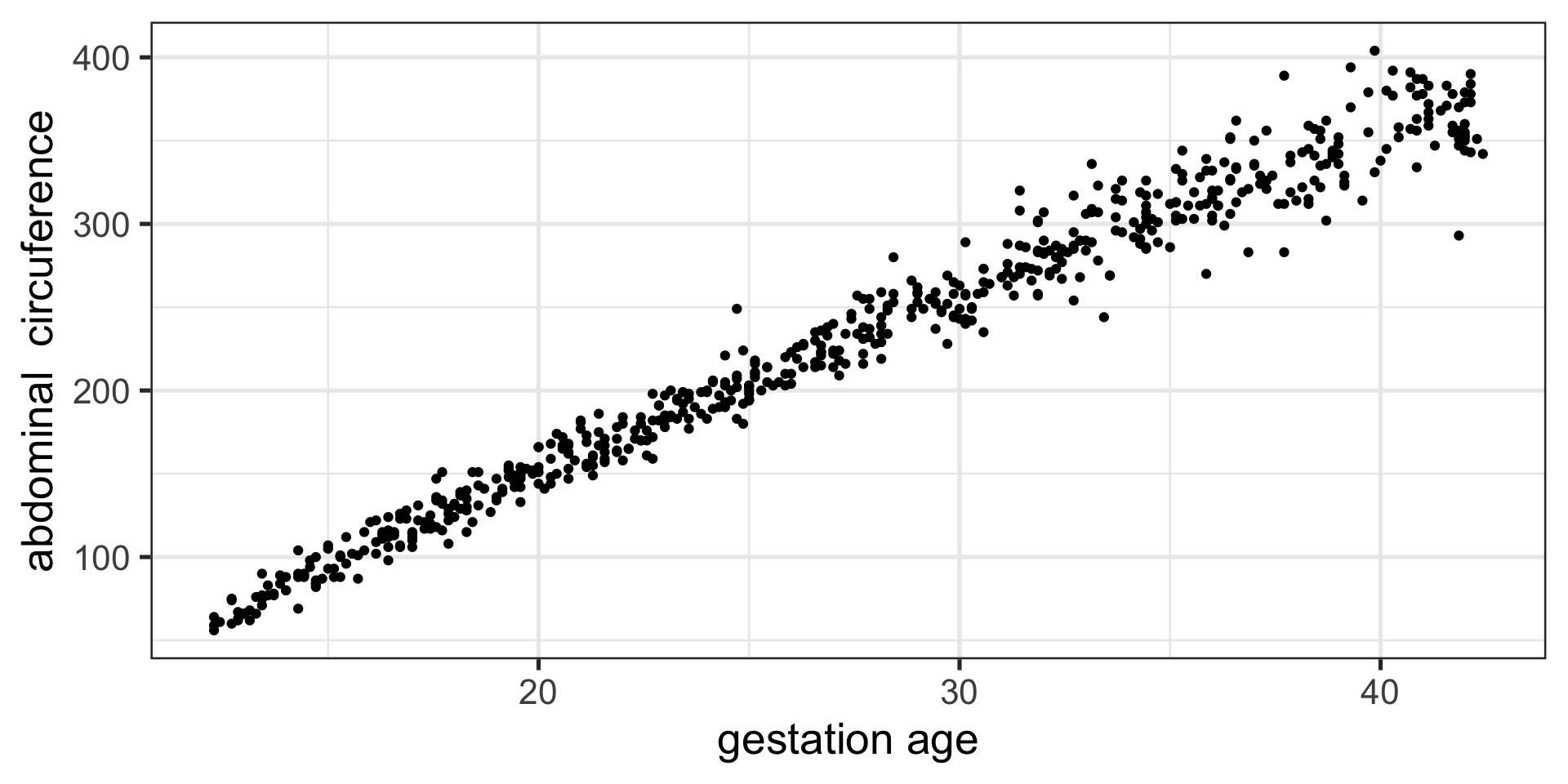
Figure 1: The abdom data.
Linear Model
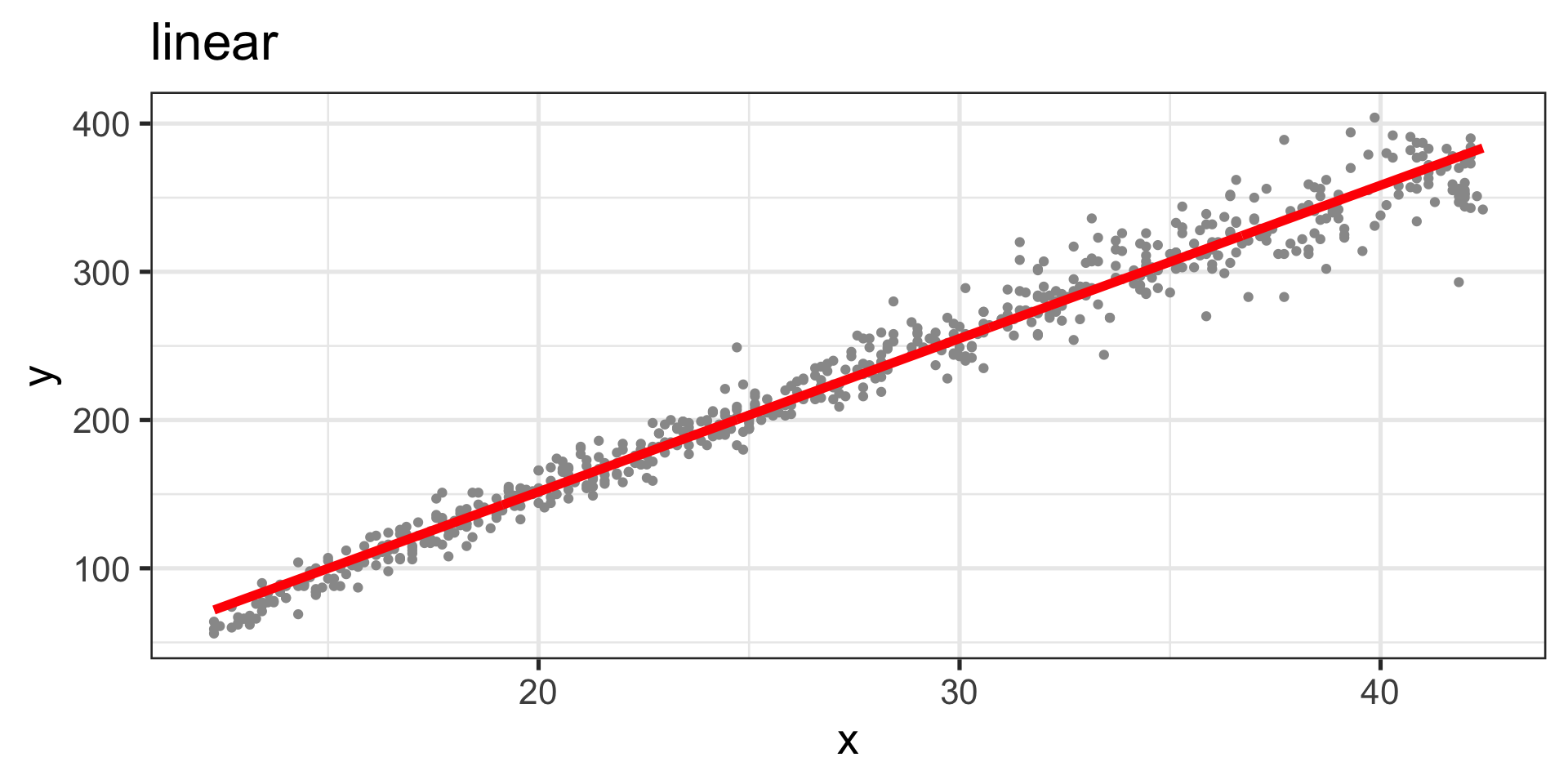
Figure 2: Fitted values, linear curve
Additive Smooth Model
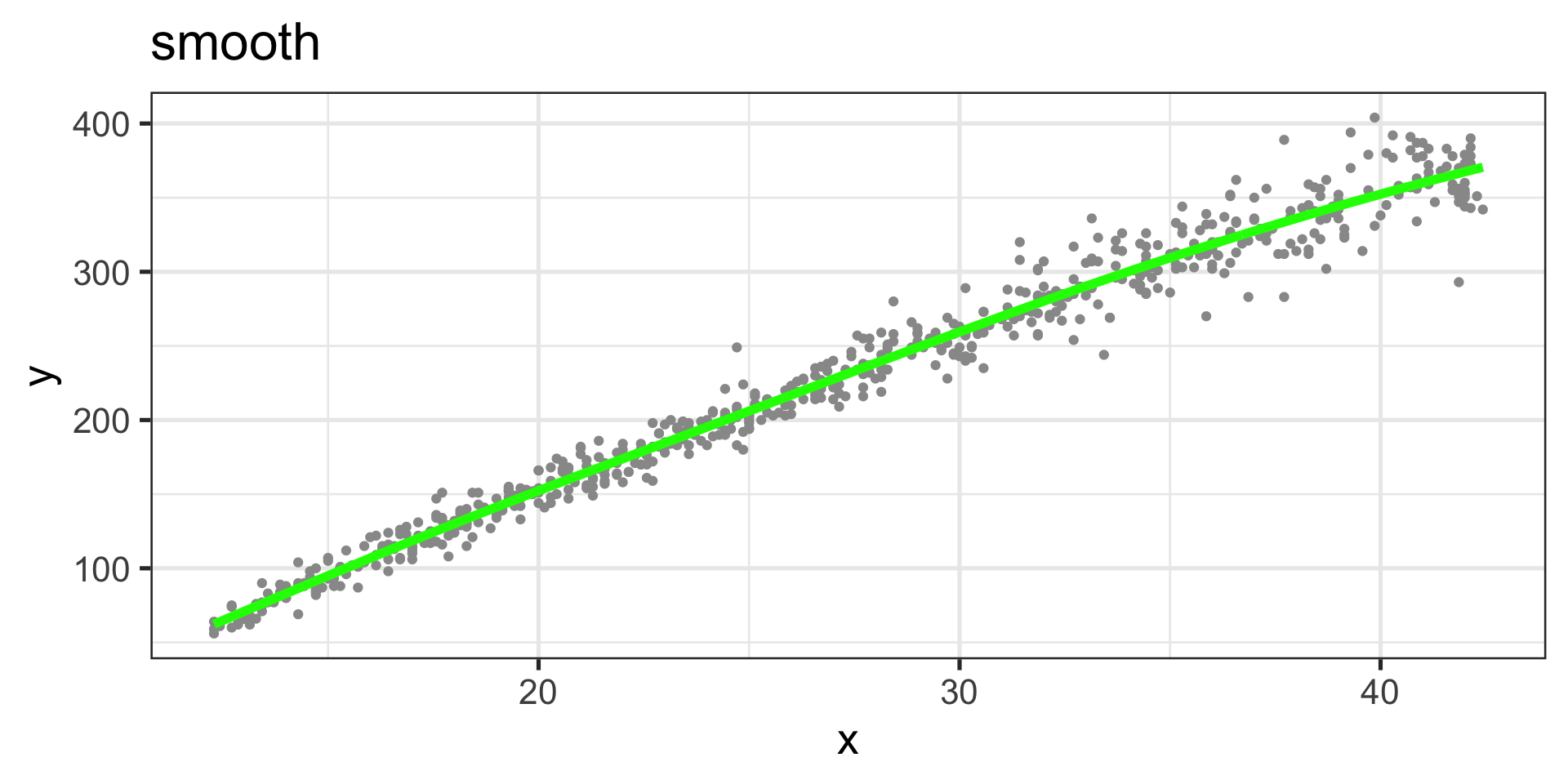
Figure 3: Fitted values, smooth curve
Neural network
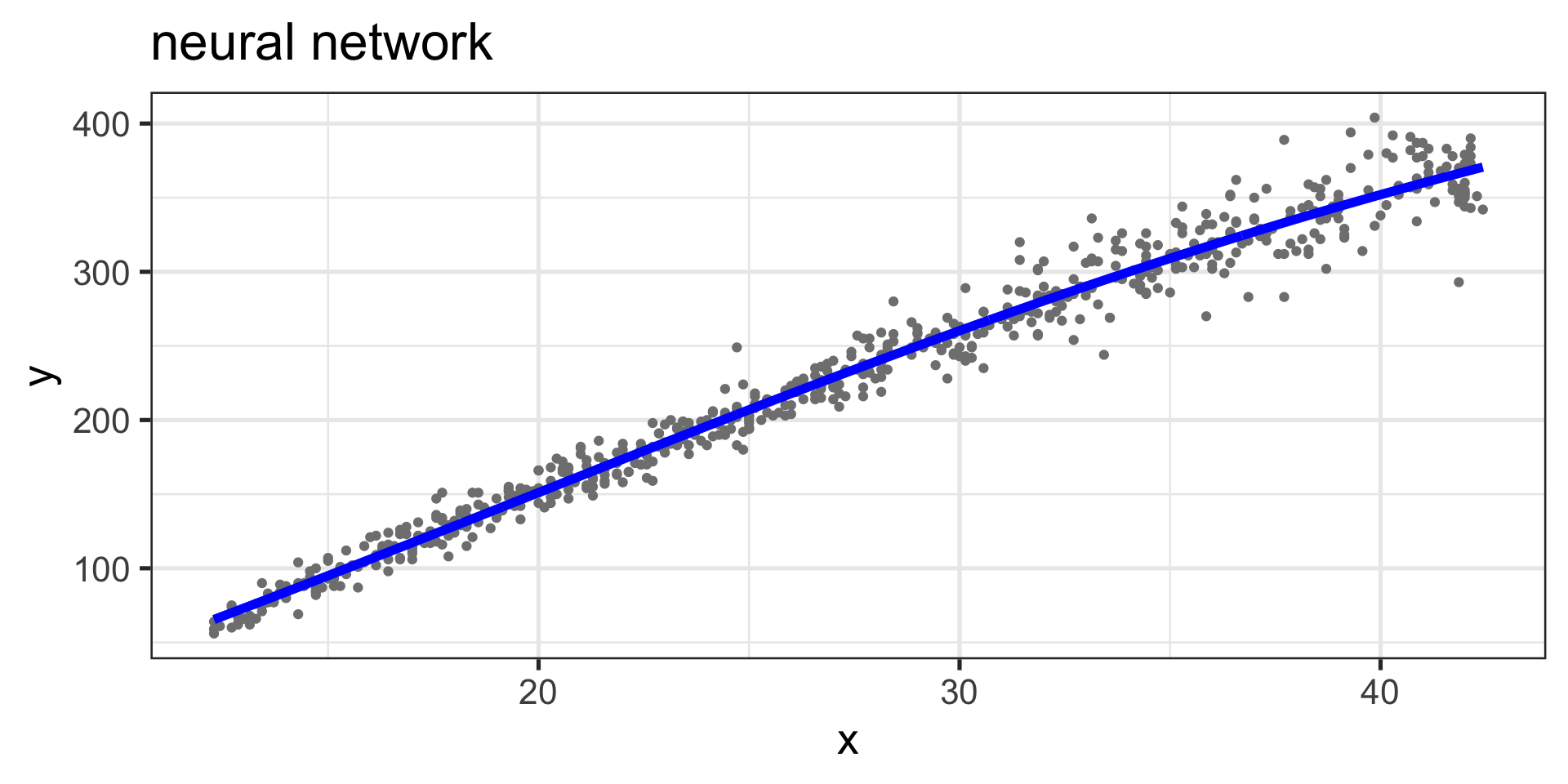
Figure 4: Fitted values, neural network curve
Regression Tree
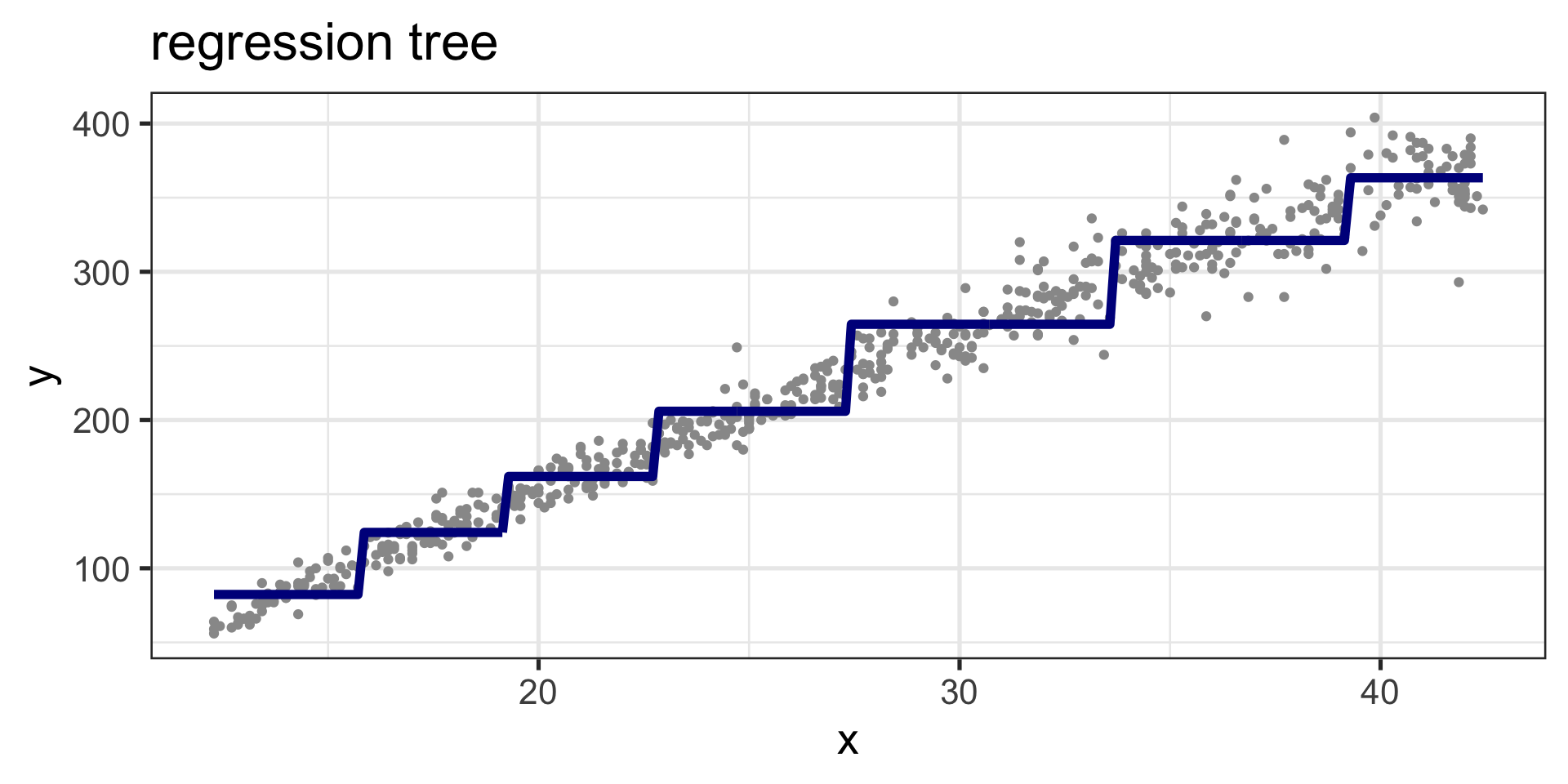
Figure 5: Fitted values, regression tree curve
Diagnostics: QQ plot
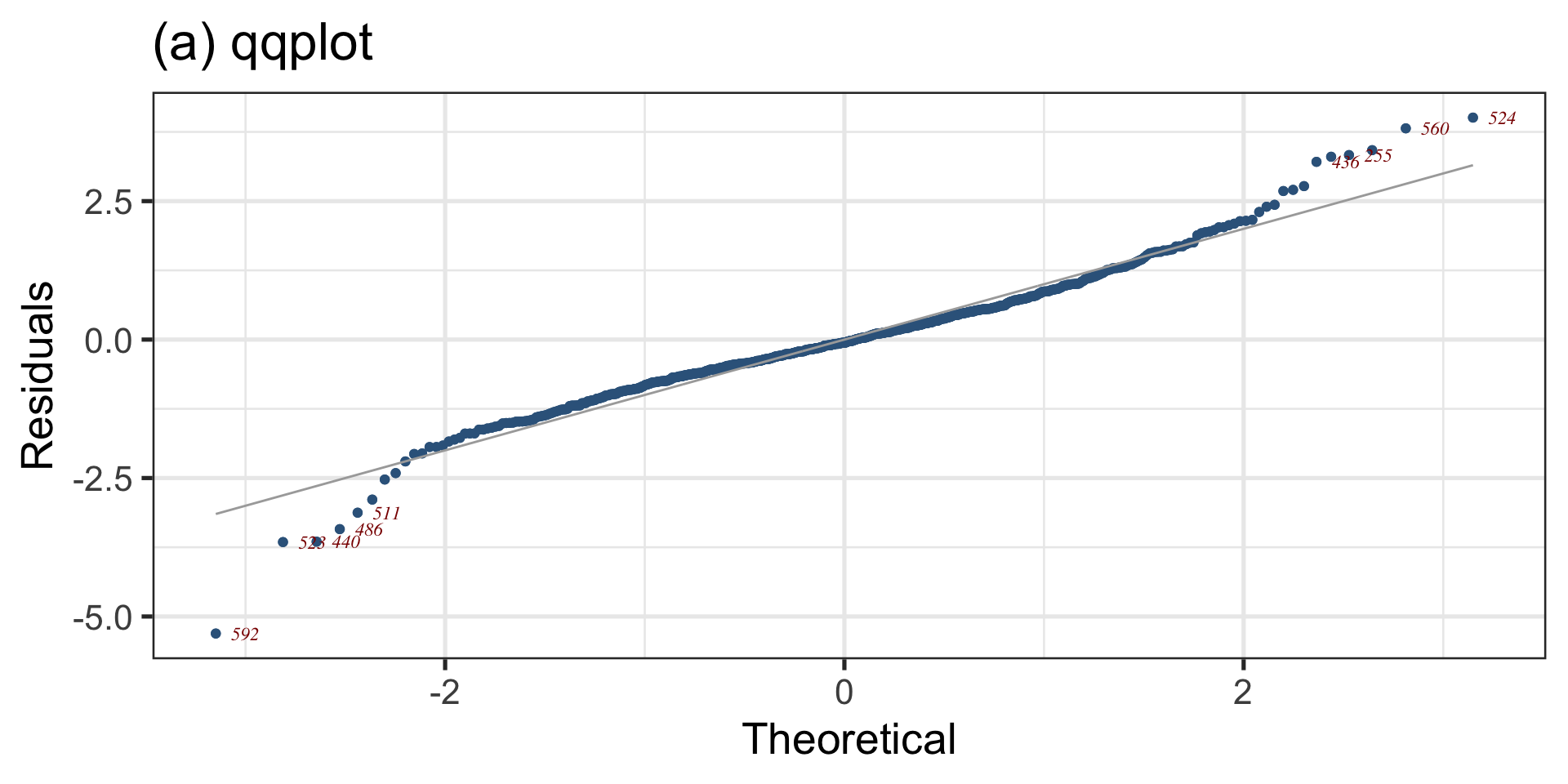
Figure 6: QQ-plot of the fitted am1 model
Diagnostics: Bucket plot

Figure 7: QQ-plot of the fitted am1 model
QQ plot, Logistic
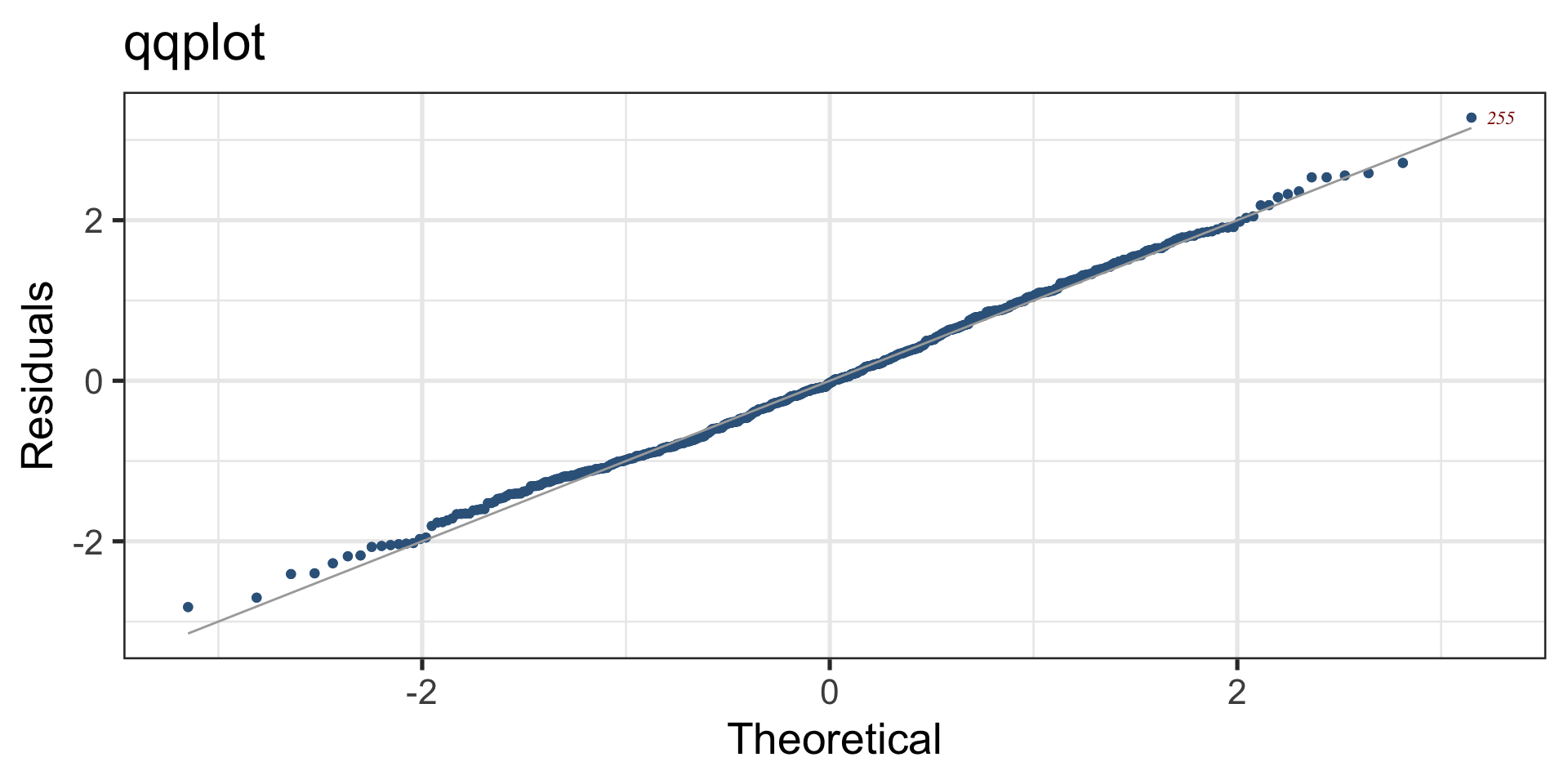
Figure 8: QQ-plot of the fitted am1 model
Bucket plot, Logistic
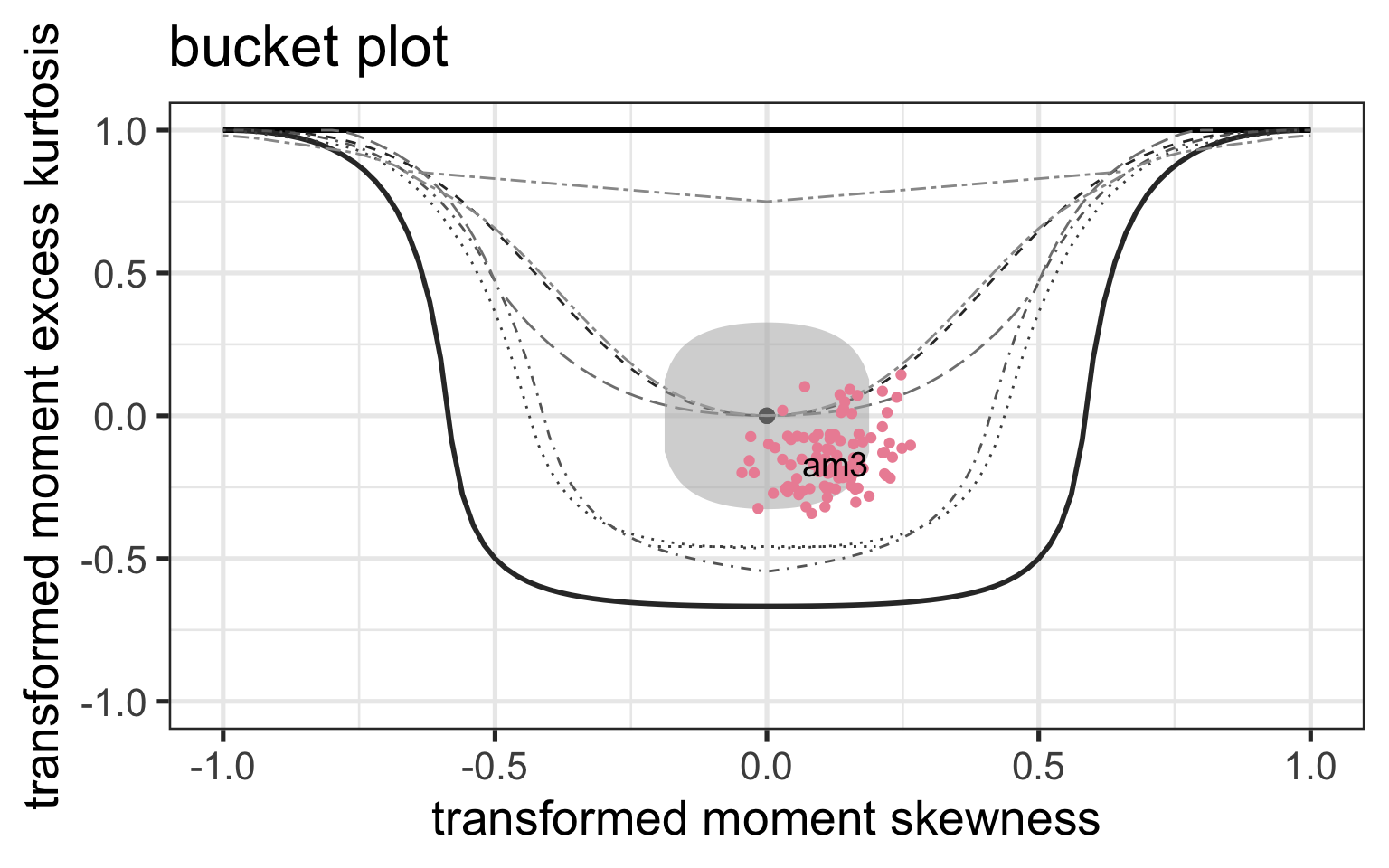
Figure 9: QQ-plot of the fitted am1 model
Fitted Centiles
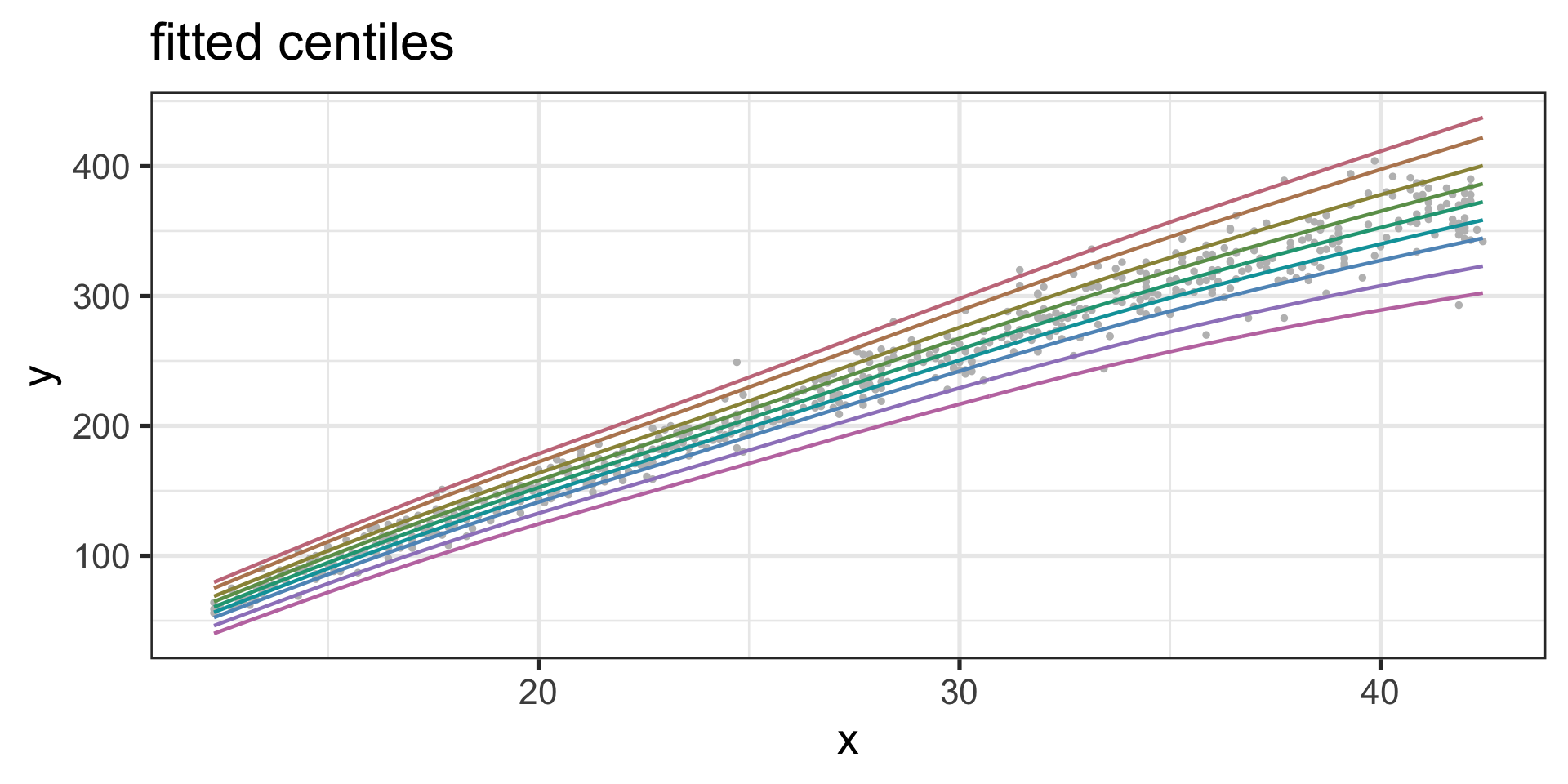
Figure 10: Centile-plot of the fitted am1 model
Fitted Distributions
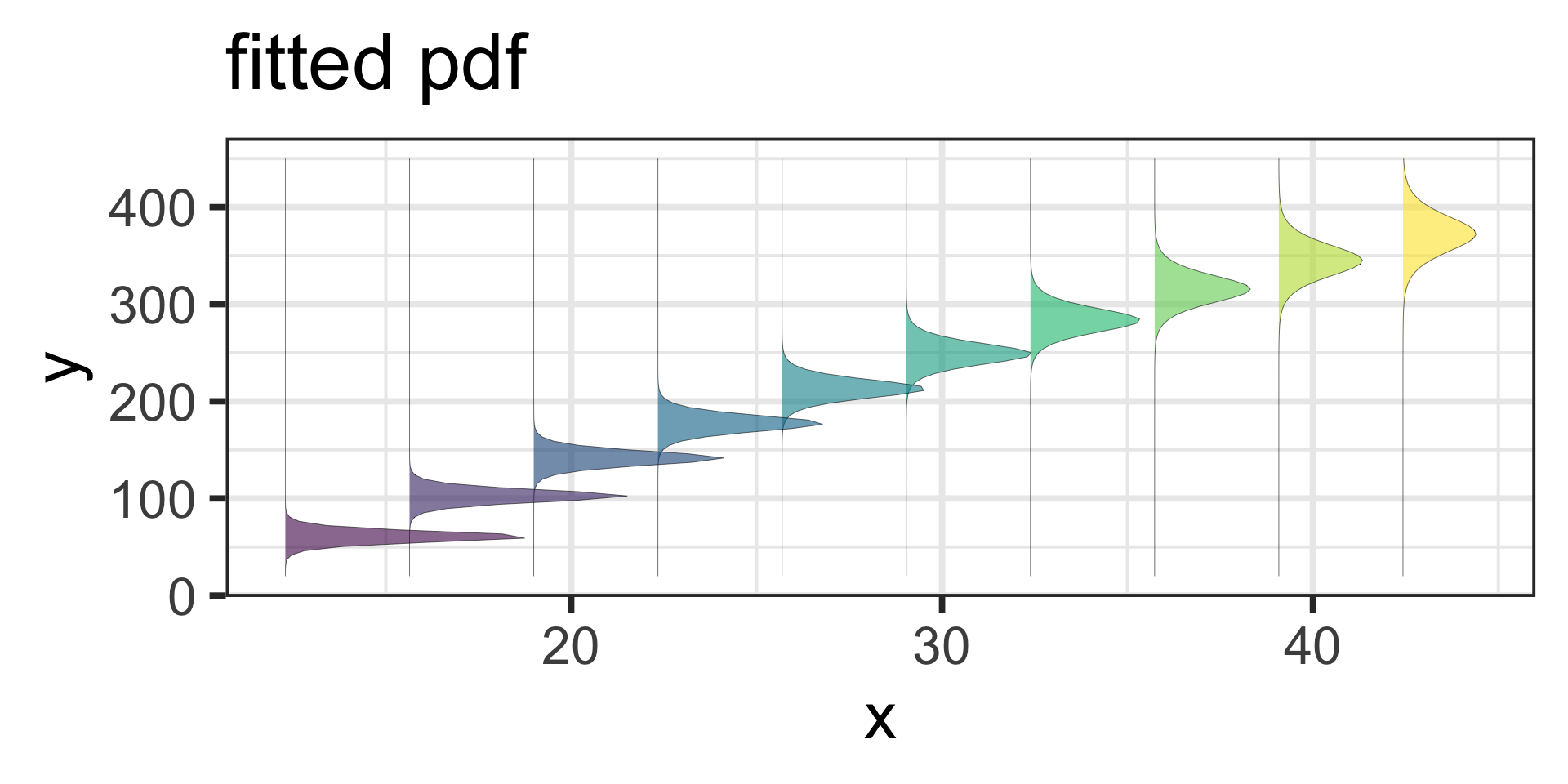
Figure 11: pdf-plot of the fitted am3 model
end


 The Books
The Books
![]()