| rent | area | yearc | location | bath | kitchen | cheating |
|---|---|---|---|---|---|---|
| 109.95 | 26 | 1918 | 2 | 0 | 0 | 0 |
| 243.28 | 28 | 1918 | 2 | 0 | 0 | 1 |
| 261.64 | 30 | 1918 | 1 | 0 | 0 | 1 |
| 106.41 | 30 | 1918 | 2 | 0 | 0 | 0 |
| 133.38 | 30 | 1918 | 2 | 0 | 0 | 1 |
| 339.03 | 30 | 1918 | 2 | 0 | 0 | 1 |
Data
data shape

(a) \(n<p\) more obstervations than variable (b) \(n>p\) more variables than obsrvations
Plotting individual vectors
data_plot()

Figure 1: Plotting the invidual variables of the data
Plotting individual vectors (1)
data_bucket()
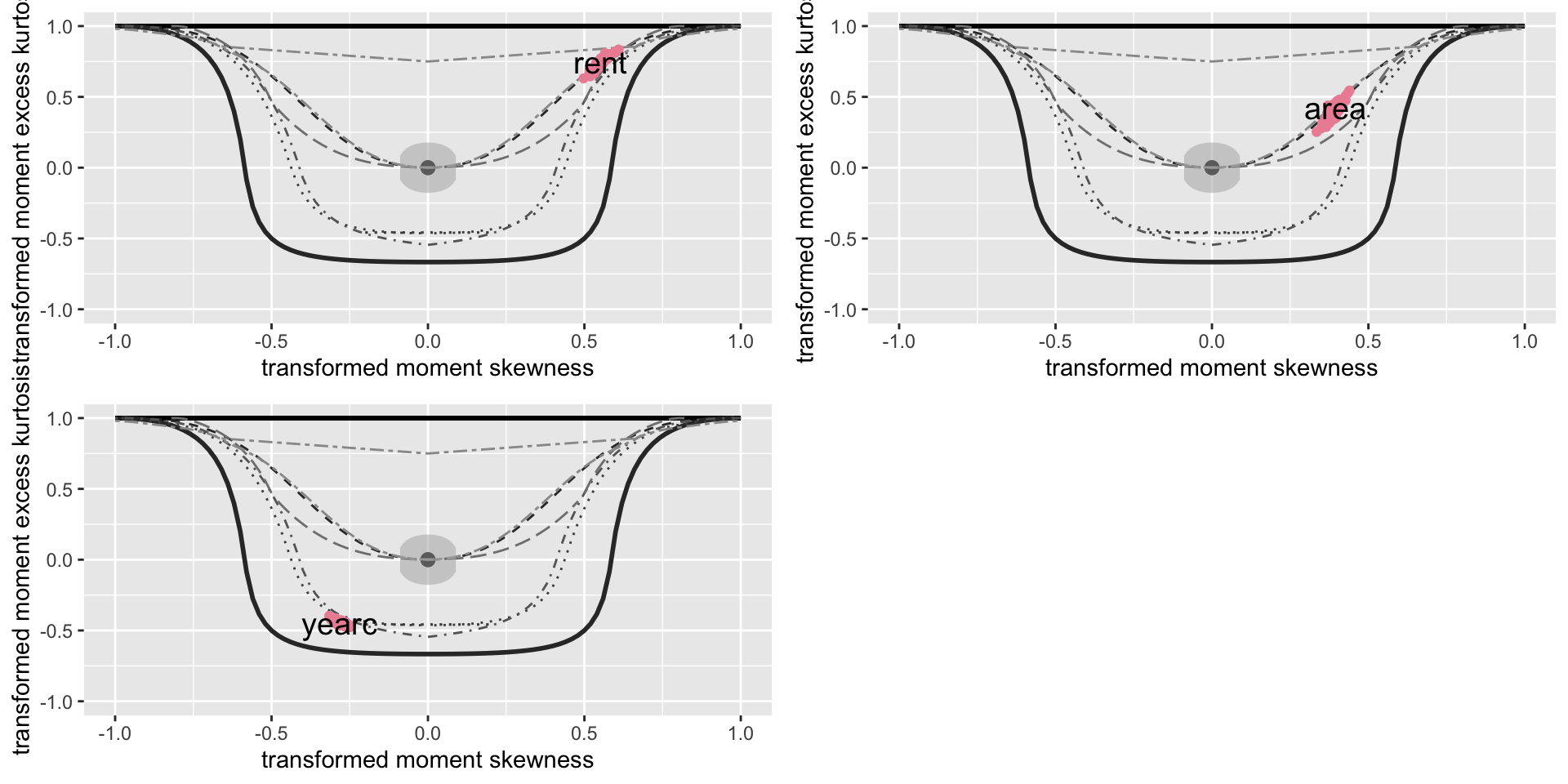
Figure 2: Plotting the bucket plot for the continuous variables in the data
Plotting individual vectors (2)
data_zscores()
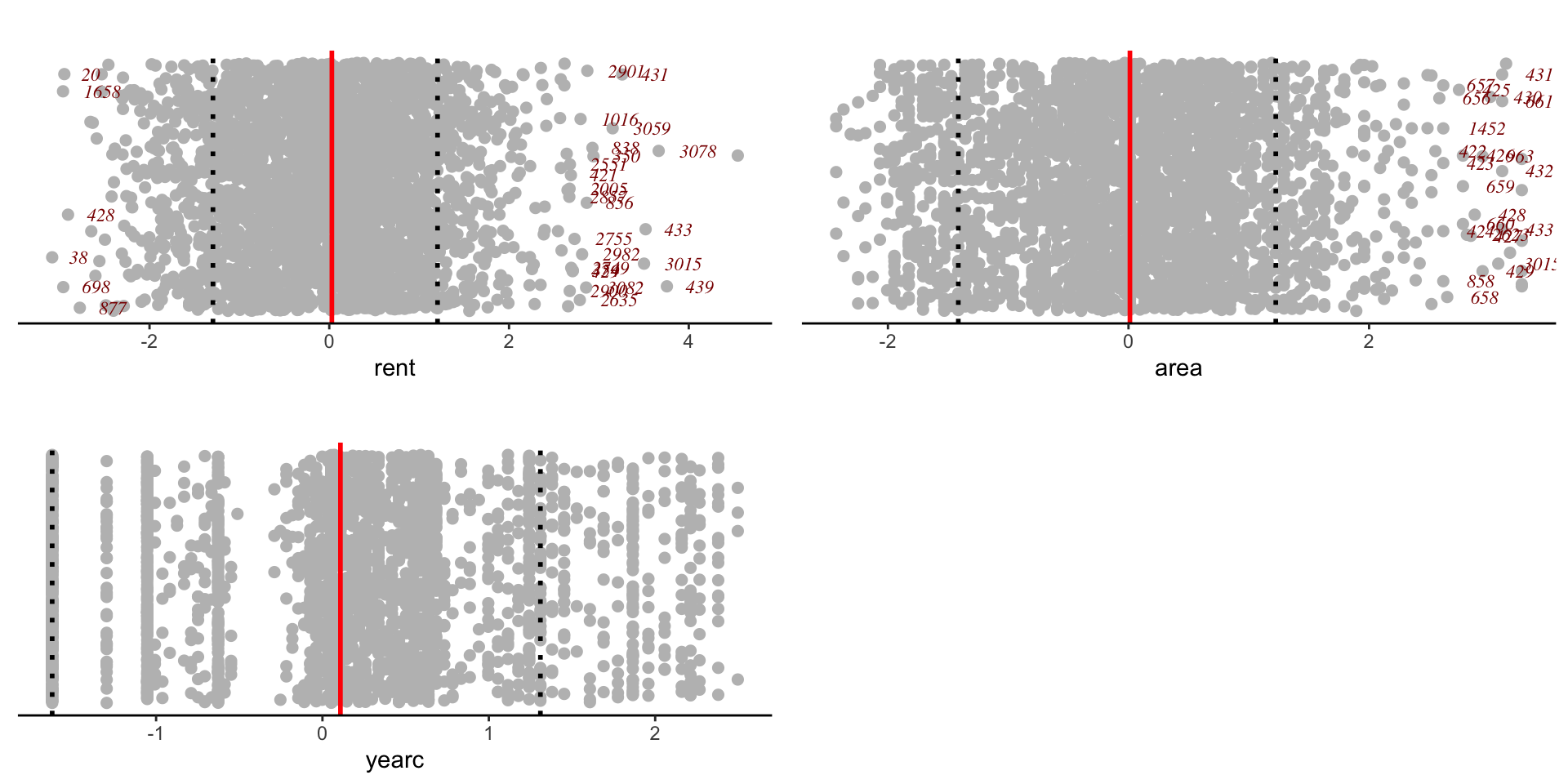
Figure 3: Plotting the histogtams of the continuous variables in the data
The response variable
the class of the response is numeric is this correct?
a continuous distribution on (0,inf) could be used 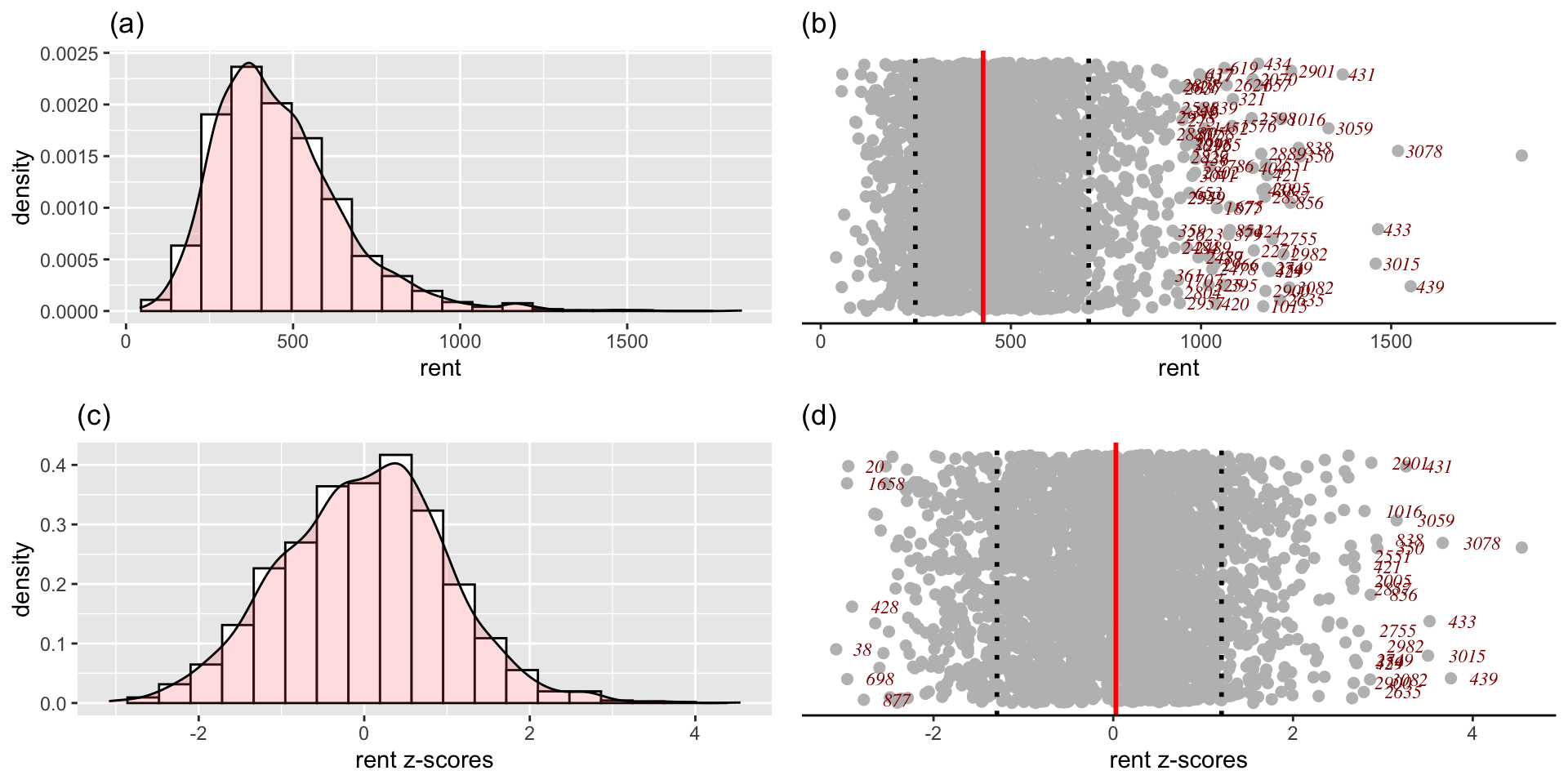
Figure 4: The response variable, (a) histogram of the response variable (b) a dot plot of the response variable (c) histogram of the z-scores of the response variable after standardised using the SHASH distribution (d) a dot plot of the z-scores of response variable.
Pair-wise data plots

Figure 5: The response variable aganst all explanatory variables.
Outliers between rows
data_leverage()
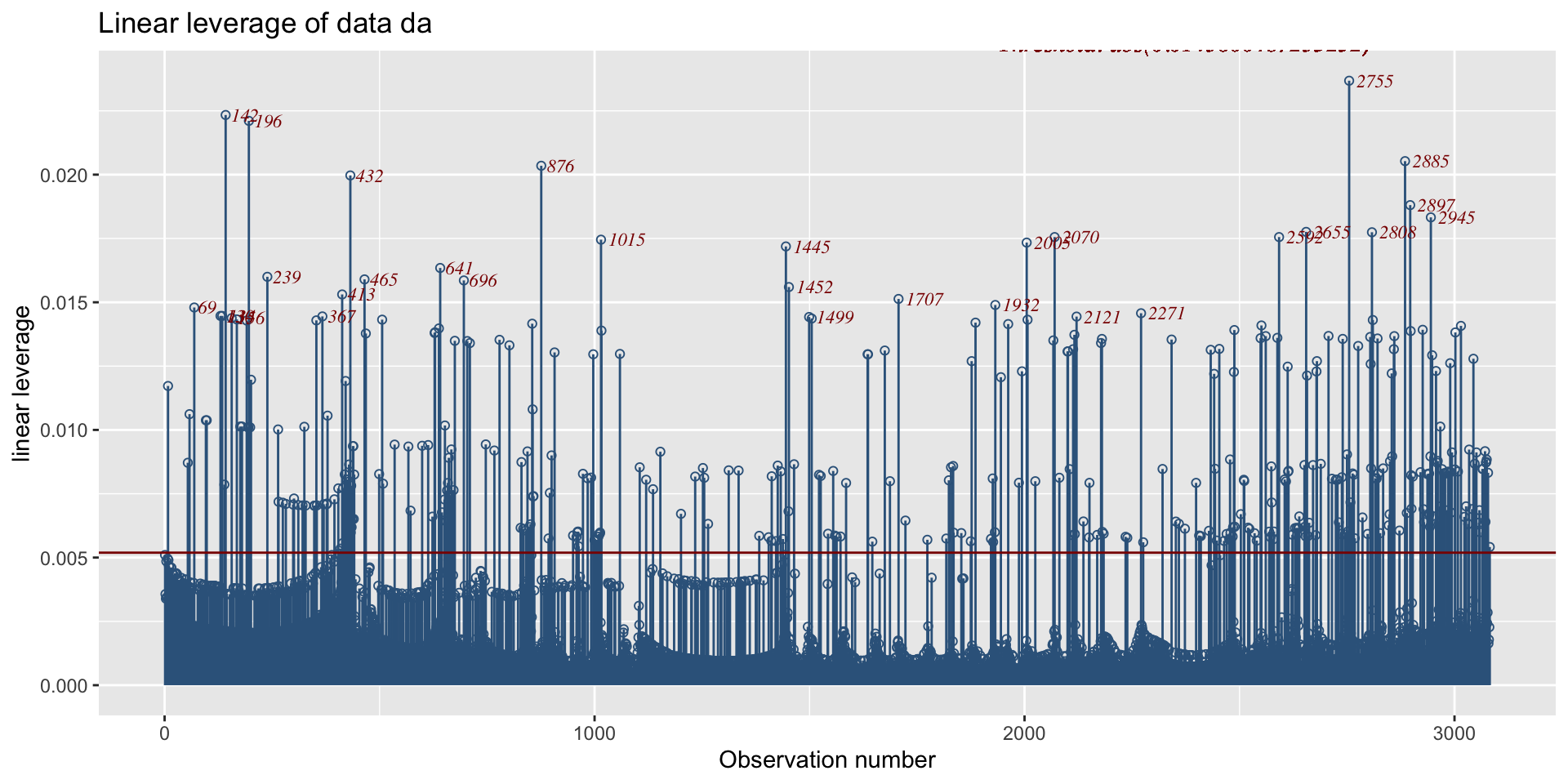
Figure 6: The observations against the linear leverage.
Transformation
data_trans()
Figure 7: The response against linear the continuous variables: on the left have no transformation, in the middle the square root ; on the right log
pair-wise linear correlations
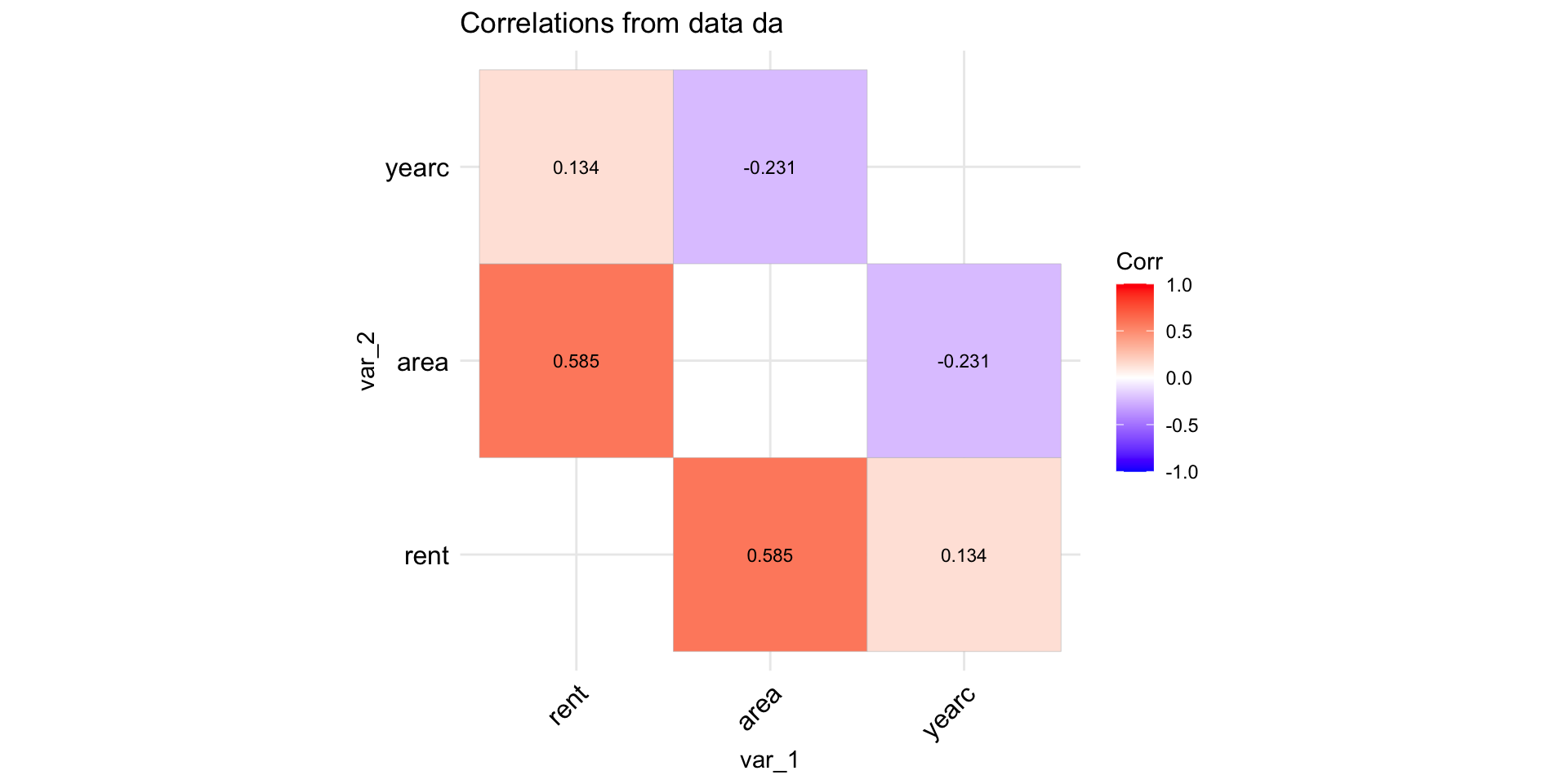
Figure 8: The linear correlation coefficients of the continuous variables in the data
pair-wise interactions

Figure 9: The pair wise interaction plots.
end


 The Books
The Books
[back](data.qmd)
![]()