what to compare
how ro compare
graphical
statistics
all
test
data partitioning
no partition
likelihood ratio
partition: evaluation is done on new data
partition
new
LS
PGD
CRPS
MAPE
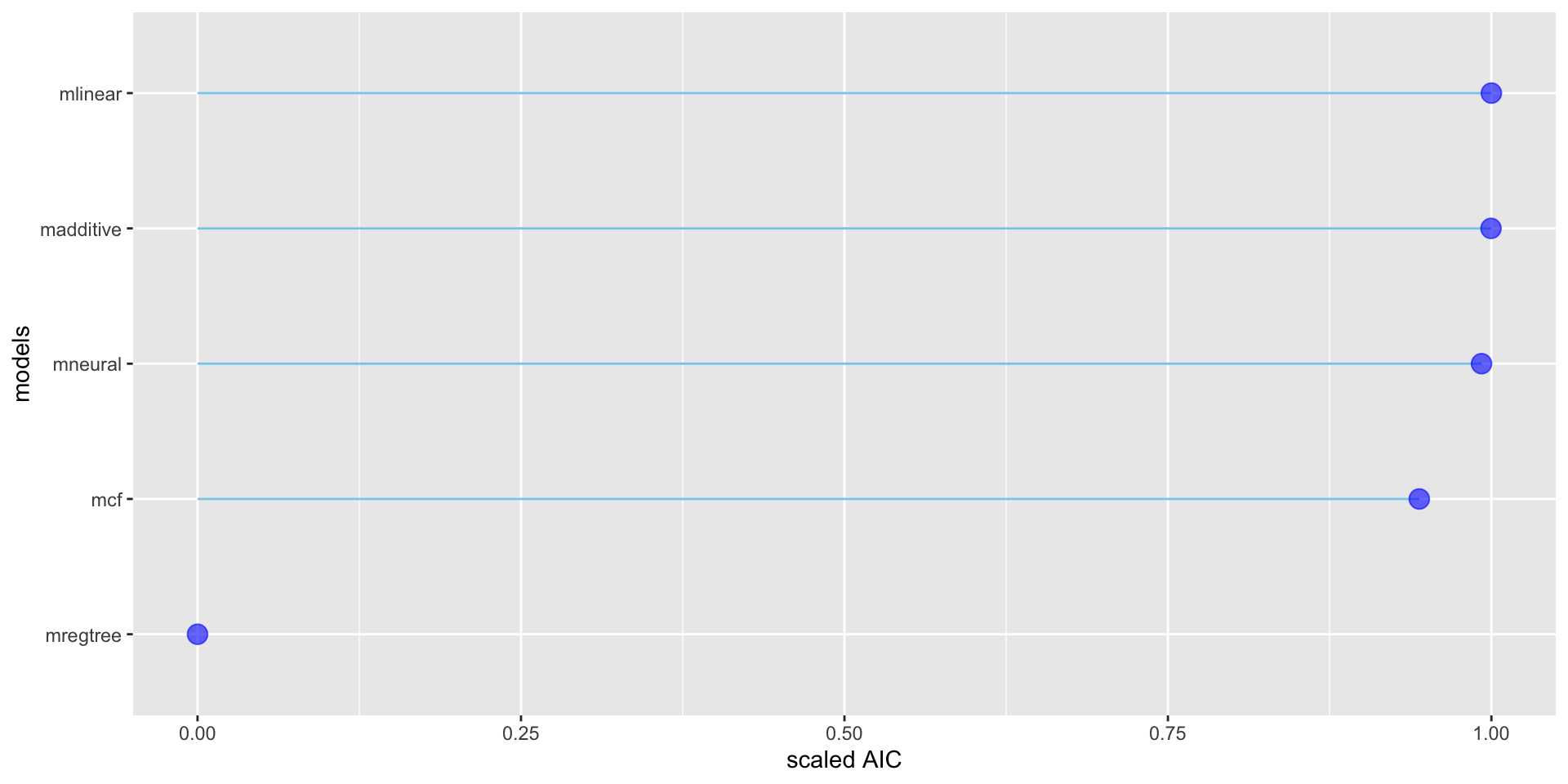
Figure 1: A lollipop plot of AIC of the fitted models.
the GAIC is well established and tested (the df of freedom need to be known)
the linear and additive model are good when there are not many explanatory variables (but somehow interactions have to be considered)
more work has to be done to standardised all ML techniques so their partitioning of data are comparable to the conventional additive models
back to the index
The Books


 The Books The Books
The Books The Books